


In this post, I’ll try using scikit’s GridSearchCV to optimize hyperparameters. GridSearchCV is a powerful tool in scikit-learn that automates the process of hyperparameter tuning by exhaustively searching through a predefined grid of parameter combinations. It evaluates each configuration using cross-validation, allowing you to identify the settings that yield the best performance. It doesn’t guarantee the globally optimal solution, but GridSearchCV provides a reproducible way to improve model accuracy, reduce overfitting, and better understand how a model responds to different parameter choices
Hyperparameter Tuning with GridSearchCV
First Attempt
The images below show the initial parameters I used in my GridSearchCV experimentation and the results. Based on my reading, I decided to try just a few parameters to start. Here are the parameters I chose to start with and a brief description of why I felt each was a good place to start.
| Parameter | Description | Why It’s a Good Starting Point |
|---|---|---|
n_estimators | Number of trees in the forest | Controls model complexity and variance; 100–300 is a practical range for balancing performance and compute. |
bootstrap | Whether sampling is done with replacement | Tests the impact of bagging vs. full dataset training—can affect bias and variance. Bagging means each decision tree in the forest is trained on a random sample of the training data. |
criterion | Function used to measure the quality of a split | Offers diverse loss functions to explore how the model fits different error structures. |
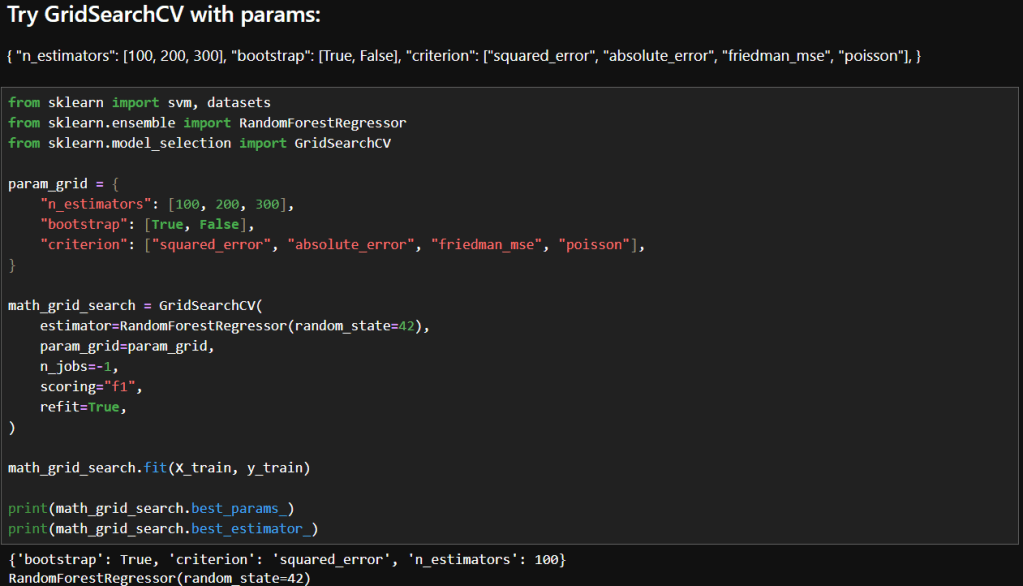

You may recall in my earlier post that I achieved these results during manual tuning:Mean squared error: 160.7100736652691
RMSE: 12.677147694385717
R2 score: 0.3248694960846078
Interpretation
My Manual Configuration Wins on Performance
- Lower MSE and RMSE: Indicates better predictive accuracy and smaller average errors.
- Higher R²: Explains more variance in the target variable.
Why Might GridSearchCV Underperform Here?
- Scoring mismatch: I used
"f1"as the scoring metric, which I discovered while reading, is actually for classification! So, the grid search may have optimized incorrectly. Since I’m using a regressor, I should use"neg_mean_squared_error"or"r2". - Limited search space: My grid only varied
n_estimators,bootstrap, andcriterion. It didn’t explore other impactful parameters likemin_samples_leaf,max_features, ormax_depth. - Default values: GridSearchCV used default settings for parameters like
min_samples_leaf=1, which could lead to overfitting or instability.
Second Attempt
In this attempt, I changed the scoring to neg_mean_squared_error. What that does is, it returns the negative of the mean squared error, which makes GridSearchCV minimize the mean square error (MSE). That in turn means that GridSearchCV will choose parameters that minimize large deviations between predicted and actual values.
So how did that affect results? The below images show what happened.


While the results aren’t much better, they are more valid because it was a mistake to use F1 scoring in the first place. Using F1 was wrong because:
- The F1 score is defined for binary classification problems. and I am fitting continuous outputs.
- F1 needs discrete class labels, not continuous outputs.
- When used in regression, scikit-learn would have forced predictions into binary labels, which distorts the optimization objective.
- Instead of minimizing prediction error, it tried to maximize F1 on binarized outputs.
Reflections
- The
"f1"-optimized model accidentally landed on a slightly better MSE, but this is not reliable or reproducible. - The
"neg_mean_squared_error"model was explicitly optimized for MSE, so its performance is trustworthy and aligned with my regression goals. - The small difference could simply be due to random variation or hyperparameter overlap, not because
"f1"is a viable scoring metric here.
In summary, using "f1" in regression is methodologically invalid. Even if it produces a superficially better score, it’s optimizing the wrong objective and introduces unpredictable behavior.
In my next post I will try some more parameters and also RandomizedSearchCV.
– William

Leave a comment