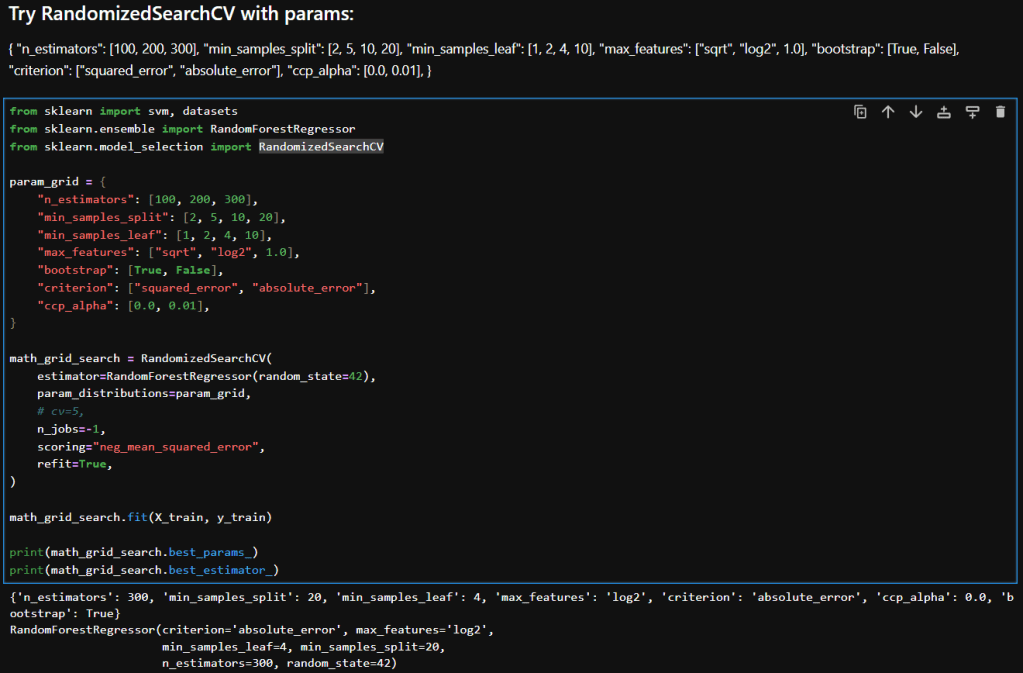
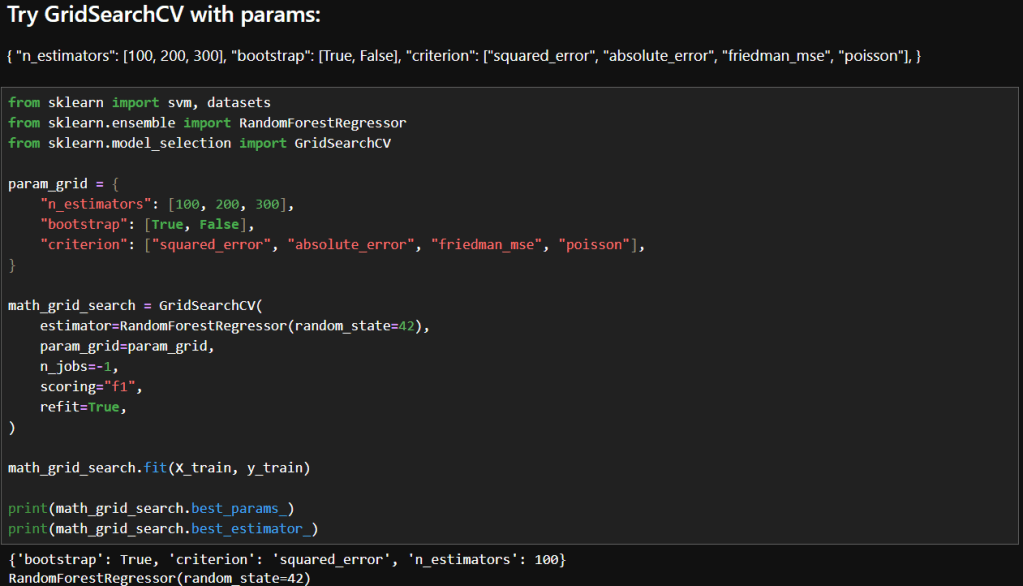
This post will be the first in a series of blog posts, called “Data Science in the World,” where I discuss the implementation of data science in different fields like sports, business, medicine, etc. To begin this series, I will be explaining how data science is used in soccer.
There are 5 main areas of the soccer world where data science plays a critical role: Tactical & Match Analysis, Player Development & Performance, Recruitment & Scouting, Training & Recovery, and Set-Piece Engineering. I will break down how data science is used in each of these areas.
Tactical & Match Analysis
- Expected Goals (xG): Quantifies shot quality based on location, angle, and defensive pressure. xG can be used to determine a player’s ability as if they generate a high xG throughout a season or their career, then they should hypothetically produce a high amount of goals eventually.
- Heatmaps & Passing Networks: Reveal spatial tendencies, player roles, and team structure. Heatmaps and passing networks can be used by coaches to point out the good and bad their team does in matches, helping them determine what to fix and what to focus on in matches.
- Opponent Profiling: Teams dissect rivals’ patterns to exploit weaknesses and tailor game plans.
Player Development & Performance
- Event Data Tracking: Every pass, tackle, and movement is logged to assess decision-making and execution. Event data tracking helps coaches and players analyze match footage to refine first touch, scanning habits, and off-ball movement.
- Wearable Tech: GPS and accelerometers monitor load, speed, and fatigue in real time. This helps tailor training intensity and reduce injury risk, especially in congested fixture periods.
- Custom Metrics: Clubs build proprietary KPIs to evaluate players beyond traditional stats. Custom metrics allow for more nuanced evaluation than traditional stats like goals or tackles.
Recruitment & Scouting
- Market Inefficiencies: Data helps identify undervalued talent with specific skill sets. This is useful for teams who do not have as much money to spend on players who are elite at multiple skills when the team only needs the player to be elite in one skill.
- Style Matching: Algorithms compare player profiles to team philosophy—think “find me the next Lionel Messi.” This ensures recruits aren’t just talented, but tactically compatible—saving time and money.
- Injury Risk Modeling: Predictive analytics flag players with high susceptibility to injury. It informs transfer decisions and contract structuring.
Training & Recovery Optimization
- Load Management: Data guides intensity and volume to prevent overtraining. Especially vital for youth development and congested schedules.
- Recovery Protocols: Biometrics and sleep data inform individualized recovery strategies. This improves performance consistency and long-term health.
- Skill Targeting: Coaches use analytics to pinpoint technical weaknesses and design drills accordingly.
Set-Piece Engineering
- Spatial Analysis: Determines optimal corner kick types (in-swing vs. out-swing) and free kick setups. It turns set pieces into high-probability scoring opportunities.
- Simulation Tools: VR and AR are emerging to rehearse scenarios with data-driven precision.
Player Examples
Now that we discussed how data science is used, I will provide examples of teams and players that utilized data science in these ways.
- Liverpool FC – Recruitment & Tactical Modeling
- Liverpool built one of the most advanced data science departments in soccer, led by Dr. Ian Graham. Using predictive models and custom metrics, they scouted and signed undervalued talent like Mohamed Salah and Sadio Mane off the basis of expected threat.
- Result: Salah scored 245 goals in just 9 seasons. Liverpool won their first Champions League title since 2005 and their first ever English Premier League title in their history with Salah and Mane leading the lines.
- Kevin De Bruyne – Contract Negotiation via Analytics FC
- De Bruyne worked with Analytics FC to create a 40+ page data-driven report showcasing his value to Manchester City. It included proprietary metrics like Goal Difference Added (GDA), tactical simulations, and salary benchmarking.
- Result: He negotiated his own contract extension without an agent, using data to prove his irreplaceable role in City’s system.
- Arsenal FC – Injury Risk & Youth Development
- Arsenal integrated wearable tech and biomechanical data to monitor player load and injury risk. Young players like Myles Lewis-Skelly used performance analytics to support their rise from academy to first team.
- Result: Lewis-Skelly’s data-backed contract renewal included insights into his match impact, fatigue management, and tactical fit—helping him secure a long-term deal amid interest from top European clubs.
References
- The New York Times. How Liverpool Became the World’s Smartest Soccer Club (Ian Graham feature).
https://www.nytimes.com/2019/05/22/sports/liverpool-champions-league.html - The Athletic. Inside Liverpool’s data revolution under Ian Graham.
https://theathletic.com/3838128/2022/11/18/liverpool-data-ian-graham/ - StatsBomb. Expected Threat (xT): The model behind modern attacking analytics.
https://statsbomb.com/articles/soccer/introducing-expected-threat-xthreat/ - Kevin De Bruyne & Data-Driven Contract Negotiation
The Athletic. How Kevin De Bruyne used data to negotiate his own contract.
https://theathletic.com/2474565/2021/04/07/kevin-de-bruyne-contract-analytics/ - Analytics FC. Goal Difference Added (GDA) and player value modeling.
https://analyticsfc.co.uk/2021/04/07/goal-difference-added/ - BBC Sport. KDB’s self-negotiated deal and analytics involvement.
https://www.bbc.com/sport/football/56669587 - Arsenal FC, Injury Prevention & Youth Development
Arsenal.com. How Arsenal uses sports science and performance data.
https://www.arsenal.com/news/how-science-shapes-our-training - Premier League Elite Player Performance Plan (EPPP). Wearable tech, GPS tracking, and youth development analytics.
https://www.premierleague.com/youth/EPPP - The Athletic. Inside Arsenal’s academy and the rise of Myles Lewis-Skelly.
https://theathletic.com/4928020/2023/10/04/arsenal-lewis-skelly-academy/